

구글이 클라우드 서비스처럼 기계학습 전용 클라우드 슈퍼컴퓨터를 제공하는 베타 서비스를 시작했다.
기계학습은 대량 데이터를 활용해야 하는 만큼 막대한 연산 처리를 위한 장비와 많은 시간이 소요돼 어려움을 겪는 경우가 많았다.
구글이 클라우드 서비스로 전용 슈퍼컴퓨터를 이용할 수 있는 서비스를 제공하면서 이러한 장비를 갖추지 못한 기계학습 연구원과 엔지니어도 며칠이 걸릴 수 있는 기계학습 작업량을 보다 짧은 시간에 완료할 수 있을 것으로 보인다.

구글은 최근 기계학습 전용 클라우드 슈퍼컴퓨터 ‘클라우드 TPU v2 팟’과 ‘클라우드 TPU v3 팟’의 베타 서비스를 시작했다고 밝혔다.
클라우드 TPU팟은 기계학습 과정에서 발생하는 막대한 연산 처리를 해결하기 위해 구글이 개발 중인 머신러닝과 텐서플로 전용 프로세서인 텐서프로세싱유닛’(TPU)를 기반으로 한 슈퍼컴퓨터다. 기술 개발 과정으로 보면 3세대 TPU 제품이라고 할 수 있다.
1세대 TPU는 학습된 모델을 사용한 추론 연산, 즉 이미지나 언어 등의 인식에 사용됐다. 머신러닝 연산은 학습과 추론, 2가지로 나뉜다. 학습에 수반되는 '모델 대상 패턴매칭' 연산은 TPU가 아니라 CPU 및 GPU가 담당했다.
2세대인 클라우드TPU는 머신러닝 연산 과정의 전반적인 연산을 담당해 전체적으로 높은 성능을 낼 수 있도록 제작됐다.
3세대인 클라우드 TPU 팟은 클라우드 TPU를 다수 연결한 멀티 랙 형태다. 클라우드 방식으로 다수의 코어를 동시에 사용하는 만큼 하나의 작업에 집중해 사용할 있을 뿐 아니라 필요에 따라 코어 수를 조정할 수도 있다.
구글이 공개한 클라우드 TPU v3 팟은 1천개 이상의 코어가 연결된 최상위 제품으로 최대 성능을 낼 경우 세계 상위 5위권 슈퍼 컴퓨터와 비슷한 수준인 100 페타플롭 이상의 컴퓨팅 성능을 제공하며 수냉식 쿨링 시스템을 지원한다. 다만 아직 타 슈퍼컴퓨터에 비해 연산 정밀도는 높지 않은 것으로 알려졌다.
하위 버전인 클라우드 TPU v2 팟은 총 512개의 코어가 포함된 총 256개의 TPU 칩을 연결하는 방식으로 11.5 페타플롭 컴퓨팅 성능을 제공한다.
구글은 TPU 포드는 다른 시스템에서 완료하는 데 며칠 또는 몇 주가 걸리는 기계학습 작업 부하를 완료하는 데 단지 몇 분에서 몇 시간이 걸릴 수 있다고 밝혔다.
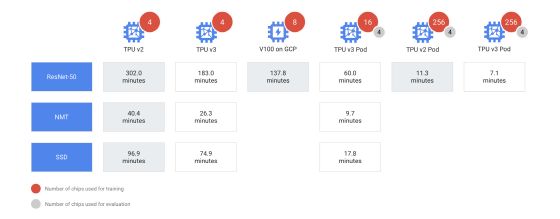
구글이 공개한 내용에 따르면 단일 TPU를 사용하면 302분이 걸리는 레스넷(ResNet-50) 모델 훈련을 v2 포드는 11.3 분, v3 포드는 7.1분만에 완료했다.
더불어 대규모 기계학습 모델 교육하는 동안 더 빠르게 반복하고, 수 페타바이트에 달하는 대규모 데이터 세트를 사용해 정확한 모델을 학습하거나 모델을 재교육하는 것과 같이 특정 요구 사항이 있는 기업에 적합하다고 구글은 소개했다.
클라우드 TPU는 구글 클라우드 페이지에서 사용 가능하다. 북미와 유럽 지역은 클라우드 TPU v3, 클라우드 TPU v2를 모두 지원하며 아시아 태평양 지역에선 클라우드 v2만 사용할 수 있다.
관련기사
- 구글, '구글 어시스턴트' 아이언맨의 '자비스' 되나?2019.05.16
- 구글·애플, 팟캐스트 바로듣기로 접근성 높였다2019.05.16
- ‘구글 I/O'서 구글이 발표한 스마트홈 제품·기능은2019.05.16
- 구글 "차세대 OS 푸크시아는 플러터 기반"2019.05.16
사용 비용은 아시아 태평양 지역 클라우드 TPU v2 기준으로 시간당 TPU별로 5.22 달러의 비용이 소요되며 유휴 자원을 다른 사용자가 요청했을 때 빌려주는 선점형 TPU는 이보다 저렴한 시간당 1.566 달러가 차감된다.
이베이의 래리 콜라지오바니 신제품 개발 담당 부사장은 “클라우드 TPU 팟은 이전 인프라보다 10배 빠른 속도로 시각적 쇼핑에 대한 접근 방식을 변화시켰다. 예전에는 이미지 인식 모델을 학습시키는 데 몇 달이 걸렸는데, 지금은 며칠만에 훨씬 더 정확한 모델을 학습시킬 수 있다”며 “또한 클라우드 TPU 팟의 추가 메모리를 활용해 한 번에 더 많은 이미지을 처리할 수 있어 반복 작업을 더욱 빠르게 수행하고 이베이 고객과 판매자 모두에게 향상된 경험을 선사할 수 있게 되었다"고 밝혔다.





